本系列文章已重新編修,並在加入部分 ES6 新篇章後集結成書,有興趣的朋友可至天瓏書局選購,感謝大家支持。
購書連結 https://www.tenlong.com.tw/products/9789864344130
讓我們再次重新認識 JavaScript!
在上一篇的分享當中,我們簡單介紹了 BOM 與 DOM,也了解到 JavaScript 是怎麼透過它們提供的方法來與瀏覽器溝通。
當一個網頁被載入到瀏覽器時,瀏覽器會先分析這個 HTML 檔案,然後會依照這份 HTML 的內容解析成「DOM」 (Document Object Model,文件物件模型)。
DOM 是 W3C 制定的一個規範,它是獨立於平台與語言的標準。 換言之,只要遵守這樣的規範實作,不管是什麼平台或者是什麼語言開發,都可以透過 DOM 提供的 API 來操作 DOM 的內容、結構與樣式。
所以說,DOM 是網頁的根本,懂得 控制籃板球的人就能控制整場比賽 控制 DOM 就可以控制整個網頁,做出良好的互動體驗。
那麼在今天的分享中,我們就繼續來介紹 DOM API 查找節點的方法吧。
<script> 標籤放哪裡有差別?這個題目其實沒有標準答案,認真要講的話之後或許可以用一整篇來說明這個。
常常聽到初學者朋友問說,為什麼放在 <head> ... </head> 裡面的 JavaScript 沒有作用? 這裡我們簡單來講一下問題所在。
針對 <script> 標籤放哪裡,一般你會聽到有兩種版本:
<head> ... </head> 之間</body> 之前確實,這兩個地方都可以放置 <script> 標籤。
那麼我們來試試昨天介紹過的,先以 document.querySelector 取得 id="hello" 的節點,然後透過 textContent 來修改內容。
先來試試把 <script> 標籤放在 </body> 之前。
馬上執行看看,看起來似乎很 ok 呢,太好了!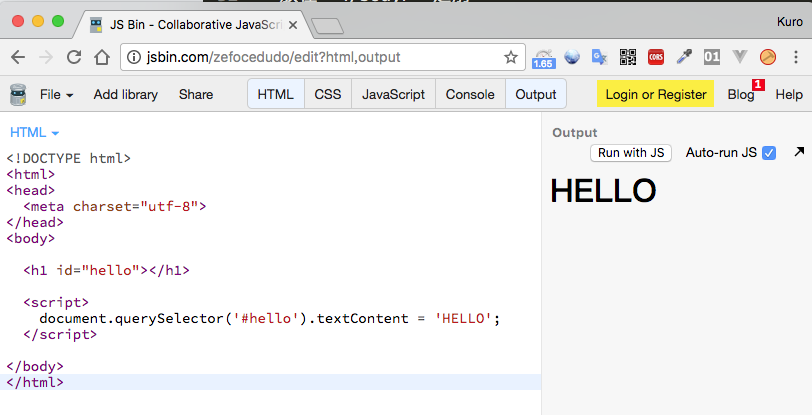
接著,我們試著把 <script> 標籤移到 <head> ... </head> 之間: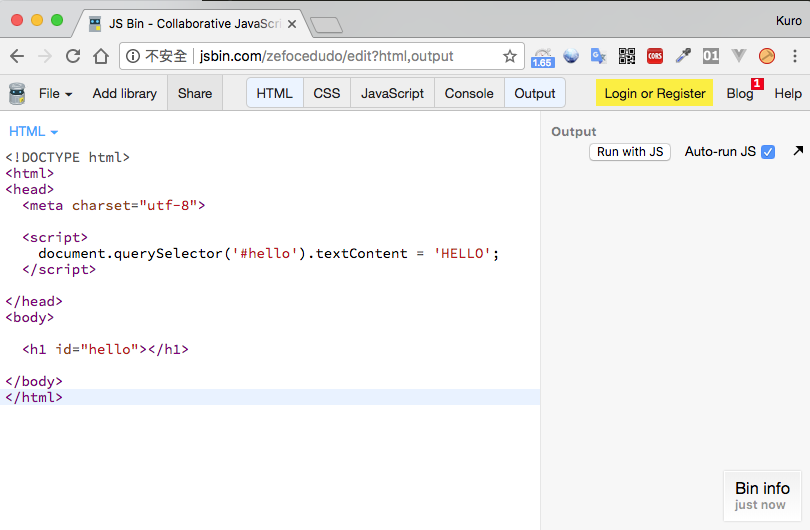
咦咦咦? 怎麼什麼都沒有?
也沒有錯誤訊息,可惡 JavaScript 你果然跟大家說的一樣,真是太雷了! (淚奔)

翻桌之前,先聽我解釋。
前面說過,當一個網頁被載入到瀏覽器時,瀏覽器會先分析這個 HTML 檔案,「由上而下」依序來讀取解析:
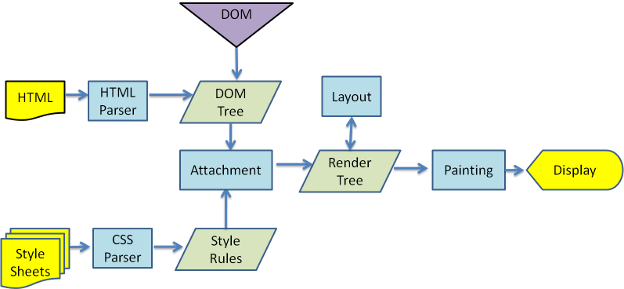
圖片來源: How browsers work
此時,當瀏覽器在 <head> ... </head> 之間遇到 <script> 標籤時,就會暫停解析網頁,並且「立即」執行 <script> 裡的內容,直到 script 執行完畢後再繼續解析網頁。
發現問題所在了嗎?
在 <head> ... </head> 裡的 <script> 想要嘗試去尋找 <div id="hello"> 這個標籤,但因為還沒解析到網頁本體,所以也無從取得。
不是瀏覽器壞掉,也不是 JavaScript 太雷,而是因為我們不理解瀏覽器執行的原理所造成的誤會。
那麼,當我們把 <script> 標籤放在 </body> 結束之前,由於 DOM 已經解析完成,所以 document.querySelector 就可以順利取得 id="hello" 的節點,並且把 'HELLO' 的字串放在網頁裡囉!
這樣說起來, <script> 標籤是不是就不適合放在 <head> ... </head> 之間呢?
也不能這麼說,這點就留待後續介紹過「事件」以及網頁效能優化的時候,再回頭來詳細解說吧!

上一篇文章說過,document 物件是 「DOM tree」 的根節點,所以當我們要存取 HTML 時,都從 document 物件開始。 而 DOM 的節點類型除了 「HTML 元素節點」 (element nodes) 外,還有「文字節點」 (text nodes)、「註解節點」 (comment nodes) 等。
而常見的 DOM 選取方法有下列這些:
// 根據傳入的值,找到 DOM 中 id 為 'xxx' 的元素。
document.getElementById('xxx');
// 針對給定的 tag 名稱,回傳所有符合條件的集合
document.getElementsByTagName('xxx');
// 針對給定的 class 名稱,回傳所有符合條件的集合
// IE9 後開始支援
document.getElementsByClassName('xxx');
// 針對給定的 Selector 條件,回傳第一個 或 所有符合條件的 NodeList。
// IE8 後開始支援
document.querySelector('xxx');
document.querySelectorAll('xxx');
document.querySelector 與 document.querySelectorAll 可以用 「CSS 選擇器」 (CSS Selectors) 來取得「第一個」或「所有」符合條件的元素集合 (NodeList)。
DOM 節點的類型常見的有下面幾種:
| 節點類型常數 | 對應數值 | 說明 |
|---|---|---|
| Node.ELEMENT_NODE | 1 | HTML 元素的 Element 節點 |
| Node.TEXT_NODE | 3 | 實際文字節點,包括了換行與空格 |
| Node.COMMENT_NODE | 8 | 註解節點 |
| Node.DOCUMENT_NODE | 9 | 根節點 (Document) |
| Node.DOCUMENT_TYPE_NODE | 10 | 文件類型的 DocumentType 節點,例如 HTML5 的 <!DOCTYPE html> |
| Node.DOCUMENT_FRAGMENT_NODE | 11 | DocumentFragment 節點 |
可以透過節點類型「常數」或是「對應數值」來判斷:
document.nodeType === Node.DOCUMENT_NODE; // true
document.nodeType === 9; // true
其他不常使用或是已經廢棄的部分可以參考:MDN Node.nodeType 一節。
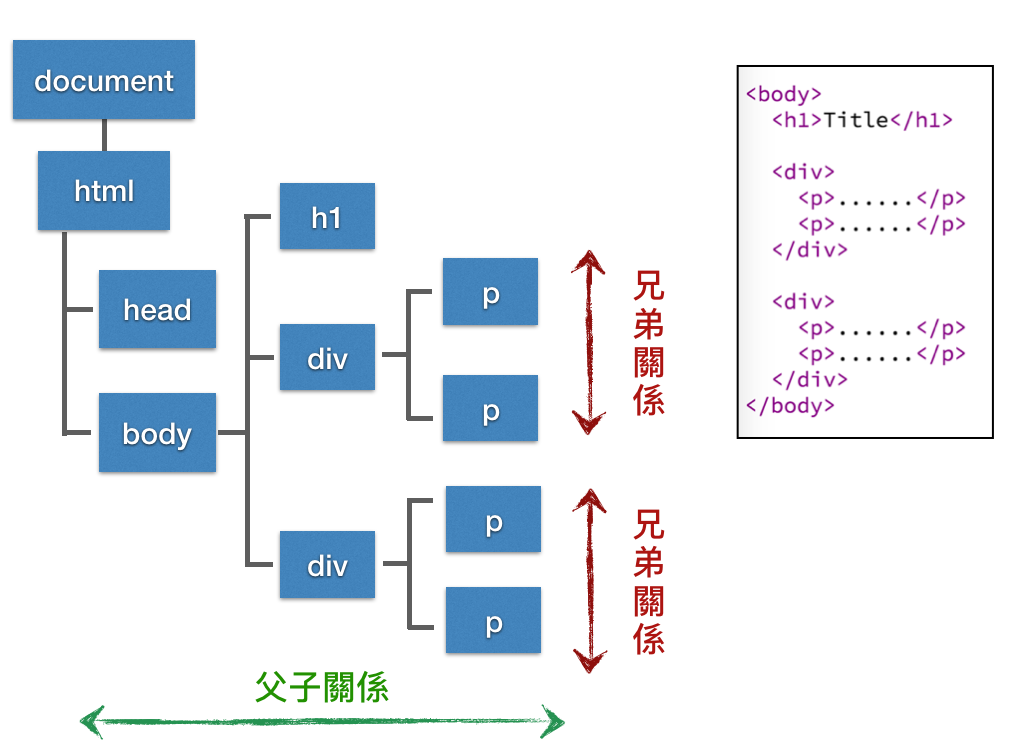
由於 DOM 節點有分層的概念,於是節點與節點之間的關係,我們大致上可以分成兩種:
父子關係:
除了 document 之外,每一個節點都會有個上層的節點,我們通常稱之為「父節點」 (Parent node),而相對地,從屬於自己下層的節點,就會稱為「子節點」(Child node)。
兄弟關係:有同一個「父節點」的節點,那麼他們彼此之間就是「兄弟節點」(Siblings node)。
當然沒有爺孫節點、也沒有表兄弟或是堂兄弟節點這種東西,隔層的節點基本上沒有直接關係。
Node.childNodes所有的 DOM 節點物件都有 childNodes 屬性,且此種屬性無法修改。
我們可以透過 Node.hasChildNodes() 來檢查某個 DOM 節點是否有子節點。
var node = document.querySelector('#hello');
// 如果 node 內有子元素
if( node.hasChildNodes() ) {
// 可以透過 node.childNodes[n] (n 為數字索引) 取得對應的節點
// 注意,NodeList 物件內容為即時更新的集合
for (var i = 0; i < node.childNodes[i].length; i++) {
// ...
};
}
Node.childNodes 回傳的可能會有這幾種:
Node.firstChildNode.firstChild 可以取得 Node 節點的第一個子節點,如果沒有子節點則回傳 null。
要注意的是,子節點包括「空白」節點,所以像下面範例:
<p>
<span>span 1</span>
<span>span 2</span>
<span>span 3</span>
</p>
<script>
var p = document.querySelector('p');
// tagName 屬性可以取得 node 的標籤名稱
console.log(p.firstChild.tagName); // undefined
</script>
因為拿到的是 <p> 與第一個 <span> 中間的「換行字元」,所以 p.firstChild.tagName 會得到 undefined。
改成這樣:
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var p = document.querySelector('p');
// tagName 屬性可以取得 node 的標籤名稱
console.log(p.firstChild.tagName); // "SPAN"
</script>
把中間的換行與空白移除,就會得到預期中的 "SPAN" 了。
Node.lastChildNode.lastChild 可以取得 Node 節點的最後一個子節點,如果沒有子節點則回傳 null。
與 Node.firstChild 一樣的是,子節點包括「空白」節點,所以像這樣:
<p>
<span>span 1</span>
<span>span 2</span>
<span>span 3</span>
</p>
<script>
var p = document.querySelector('p');
// textContent 屬性可以取得節點內的文字內容
console.log(p.lastChild.textContent); // "" (換行字元)
</script>
得到的會是一個換行字元的空字串。
移除節點之間多餘的空白後:
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var p = document.querySelector('p');
// textContent 屬性可以取得節點內的文字內容
console.log(p.lastChild.textContent); // "span 3"
</script>
就會是正確的 "span 3" 了。
Node.parentNode那麼相較於「Child 系列」,parentNode 就單純一些。
透過 Node.parentNode 可以用來取得父元素,回傳值可能會是一個元素節點 (Element node)、根節點 (Document node) 或 DocumentFragment 節點。
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var el = document.querySelector('span');
console.log( el.parentNode.nodeName ); // "P"
</script>
Node.previousSibling看完了 DOM「父與子」之後,接著來看看兄弟節點。
透過 Node.previousSibling 可以取得同層之間的「前一個」節點,如果 node 已經是第一個節點,則回傳 null。
<p><span>span 1</span><span>span 2</span><span>span 3</span></p>
<script>
var el = document.querySelector('span');
console.log( el.previousSibling ); // null
// document.querySelectorAll 會取得所有符合條件的集合,
// 而 document.querySelectorAll('span')[2] 指的是「第三個」符合條件的元素。
var el2 = document.querySelectorAll('span')[2];
console.log( el2.previousSibling.textContent ); // "span 2"
</script>
Node.nextSibling與 Node.previousSibling 類似,透過 Node.previousSibling 可以取得同層之間的「下一個」節點,如果 node 已經是最後一個節點,則回傳 null。
// document.querySelector 會取得第一個符合條件的元素
var el = document.querySelector('span');
console.log( el.nextSibling.textContent ); // "span 2"
document.getElementsBy** 與 document.querySelector / document.querySelectorAll 的差異今天分享了很多關於 DOM 的選取以及查找遍歷的方式,其中,像是 document.getElementById 以及 document.querySelector 因爲取得的一定只會有一個元素/節點,所以不會有 index 與 length 屬性。
而 document.getElementsBy** (注意,有個 s) 以及 document.querySelectorAll 則分別回傳 「HTMLCollection」 與 「NodeList」。
這兩者其實是類似的規格實作,「HTMLCollection」只收集 HTML element 節點,而「NodeList」除了 HTML element 節點,也包含文字節點、屬性節點等。 雖然不能使用陣列型別的 method,但這兩種都可以用「陣列索引」的方式來存取內容。
另一個需要注意的地方是,HTMLCollection / NodeList 在大部分情況下是即時更新的,但透過 document.querySelector / document.querySelectorAll 取得的 NodeList 是靜態的。
什麼意思呢? 舉個例子:
<div id="outer">
<div id="inner">inner</div>
</div>
<script>
// <div id="outer">
var outerDiv = document.getElementById('outer');
// 所有的 <div> 標籤
var allDivs = document.getElementsByTagName('div');
console.log(allDivs.length); // 2
// 清空 <div id="outer"> 下的節點
outerDiv.innerHTML = '';
// 因為清空了<div id="outer"> 下的節點,所以只剩下 outer
console.log(allDivs.length); // 1
</script>
如果改成 document.querySelector 的寫法:
<div id="outer">
<div id="inner">inner</div>
</div>
<script>
// <div id="outer">
var outerDiv = document.getElementById('outer');
// 所有的 <div> 標籤
var allDivs = document.querySelectorAll('div');
console.log(allDivs.length); // 2
// 清空 <div id="outer"> 下的節點
outerDiv.innerHTML = '';
// document.querySelector 回傳的是靜態的 NodeList,不受 outerDiv 更新影響
console.log(allDivs.length); // 2
</script>
那麼以上就是今天介紹的內容。
在後續的文章會再繼續說明 DOM API 新增/刪除/修改 節點的部分,歡迎持續關注。
最後兩個比較是不是一樣,都getElementById
啊,其實要比較的是這段,但兩次貼到重複的了 (糗
// 所有的 <div> 標籤
var allDivs = document.getElementsByTagName('div');
// 所有的 <div> 標籤
var allDivs = document.querySelectorAll('div');
謝謝提醒! :)
// 所有的 <div> 標籤
var allDivs = document.querySelector('div');
Kuro 大大, allDivs 應該是 querySelectorAll 才對?
寫得超仔細的!覺得受益良多 :D
對,大家眼睛真好 (超糗



